
What if you could write a story and automatically convert it to a game? Where you just select a character and play. So you’re in a world described in the story.
Sounds too broad, but I want to achieve something like that. Yes, the game itself will look more like a quest. Stories do not contain any graphics. But you have lot of characters, their features, world with its rules and all of that stuff. And yes, I can add graphics on top of that game later.
So what should I do?
- understand story
- create world from story
- create rules by which world lives
- give player ability to control selected character
Ok, then first task is to understand a story. This is what I’ll write about now.
What do I mean by ‘understanding’? This is a deep philosophical discussion, so i won’t dive into it. Just say that in my case I need to do something like you remember (or not) from English classes from school. Its called ‘parse tree’.

Doing such things is called natural language processing and its a widely explored field (wiki1, wiki2, wiki3) . But there are huge amount of different approaches and nevertheless task is not solved and most of real applications can’t avoid dropping this task to neural networks. So when I started reading net to select parsing method, I realised that its even hard to understand them. So it will be extremely hard to extend them for my purposes. And it means only one thing: I’m doing my own new shining wheel invention.
At first I made up some grammar rules and tried to apply them as in functional languages. But it quickly became unmanageable, cause rules wanted to rely on each other, override each other and be ambiguous.
I needed order. So second try was to apply deduction – I know that text consists of sentences. Ok, split text to sentences and parse each part as sentence separately. I know that each sentence contains at least one verb if its English. Ok, find first possible verb. Then I know for sure that there should be the subject before verb. Ok, parse whats before verb as subject. And so on. This method was better, but it often I just couldn’t split parts of sentence to smaller pieces. I need to understand some words before I can impose any structure. It was clear that this algorithm cant be done without exhaustive search functionality. Ok, I added backtracking. It really helped in half cases, but in other half – everything became so complicated so it got unmanageable again.
But then I understood that this algorithm is very much suboptimal from the very beginning. People dont understand it this way. What do you do when see big unknown text? You find familiar word. Word. Or you find familiar phrase. Its bottom-to-top approach, not top-to-bottom. But we also know about sentences and stuff like that. So optimal algorithm should have capabilities to use both approaches, top-to-bottom and bottom-to-top. Therefore I m made third iteration.
Idea of the third and final (so far) iteration is “do it like human”. So I can mine my intuition as a resource. For each case in algorithm, I can put intuition to code. Of course, I should do it carefully, intuition is specific to some example. So I just give it enough different examples and extract general rule. Biggest benefit is that I can never get into “impossibly unmanageable” situation, because my intuition works, I use it every day. So each time I feel things are getting complicated, I just fall back to what intuition says and check whether my algorithm for current case is as simple as that. Sounds reasonable, so I started.
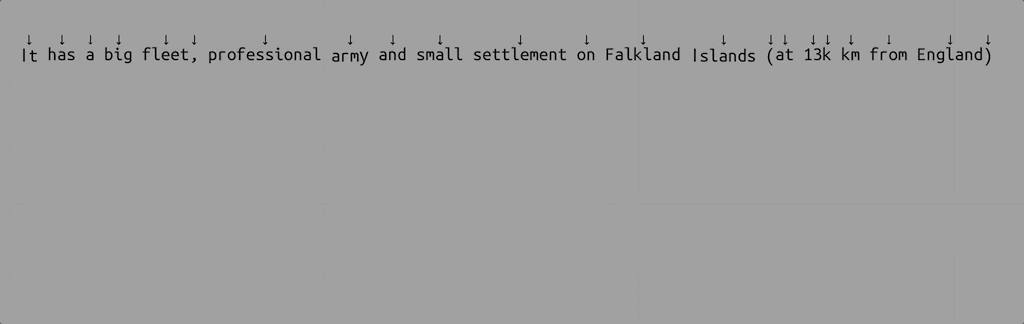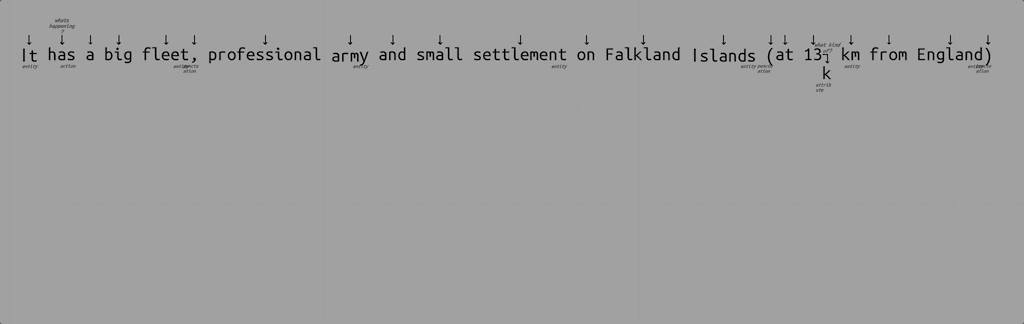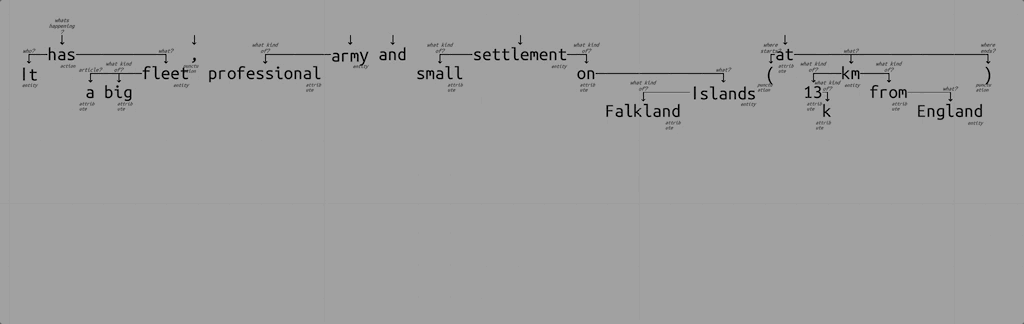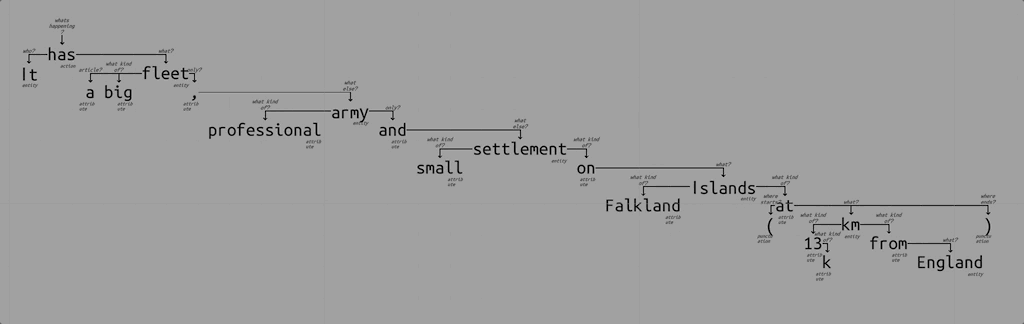
Lets assume I see this text: “It has a big fleet, professional army and small settlement on Falkland Islands (at 13k km from England)”.
What do I understand first? Verb “has”. Something has something. So I create rule that finds single verb in sentence and marks it as a sentence action. There can be different situations where this rule won’t work, so I just say that rule works when no other verbs possible in sentence.
Also I instantly see that there is some distance in the end of the sentence. “13k km” sounds familiar. So I create a rule that parses this. But in general, so it works with any measurement, just looking for a number and some unit behind it.
Continuing this process, I get ~30 rules to understand my test text (a story about Falklands war in my example). But again, how rules will interact? who applies first? what order? These are important questions, because understanding results can be different.
What if I ask my intuition about it? It says that I scan text with my eyes and apply rules on those words that I am looking at the moment. I have attention. So how to code this? Lets assume I pay attention on each word of sentence in sequence. Each rule tries to apply itself on current word, possibly checking its surroundings to fulfil some conditions (like finding noun near adjective). When sequence ended, I start over, paying attention on first word again. But this time I can rely on previously understood relations, so more complex rules will be applicable. This process runs till everything understood. Or till no rules can apply.

Sometimes its profitable to impose structure on text, like in top-to-bottom approach. I am sure that if something is in brackets then it can be parsed separately. Or if I found subsentence, it should be parsable on its own. So in some cases I leave it to recursive backtracking algorithm. But it does not replace my general algorithm which is “pay attention and apply rules”. I just can use recursiveness as an instrument in specific rules. Like “gerund subsentence” rule that finds possible subsentence, can parse it recursively.
Ok, this approach worked great until I stumble into this sentence:
President and general Leopoldo Galtieri is in power in Argentina and in command of Argentinian armed forces.
I know that president and general are the same entity attributes here. So its like:
(president and general) Leopoldo Galtieri
and in no case its like:
(president) and (general Leopoldo Galtieri)
But it cant be parsed using only grammar rules. Never. There can be no word “is” that removed ambiguousness in original sentence. Just replace “president” to “money” and see how meaning of “and” changes:
(money) and (general Leopoldo Galtieri)
But how I intuitively understand this “and” correctly? It seems like I use prior knowledge that “president” and “general” are a kind of similar concepts and they both apply on person. There can be other cases where I need some prior knowledge about concepts in text to parse it correctly. For example consider sentence with this structure:
noun verb noun to noun
What this preposition “to” relates to? Could be different, because:
(they launch torpedo) to (the cruiser)
but:
it was (400km) to (Argentina)
Same preposition “to”, same speech parts in both sentences. But different grammatical structure. Some rules even can be specific to text domain. For example if I see phrase “Type 42 destroyer”, I understand that its “destroyer of Type 42”. But some person, unfamiliar with such military-domain phrases, could easily understand it like “something about 42 destroyers”.
So what is my answer to all this problem when grammar is not enough? As my intuition principle says, I have to add prior knowledge about concepts. Previously, I had only dictionary where words claimed what speech parts they can be:
Now I add prior understanding about concepts:

“Known Concepts” work transitively, so if Lviv is a city and a city is a place, I understand that Lviv is a some kind of place. So “Known Relations” allows me to judge in ambiguous situations. I just find known relations and prefer them.

Awesome, it all works now. As a warning, I have to tell that I made text parsing specifically for my case, tested on the only one text. Nevertheless, I plan to use it in future in more cases, so it has clear points of extension:
- dictionary, where words claim what speech parts can they be. Unknown words parse as nouns or adjectives. But I can easily add words to the dictionary or even import real dictionary if needed.
- rules. Each of them is pretty separate from others and has a clear human sense. And its clear how rule will embed in whole system (using that attention-based approach I described). So I can add rules easily when needed. For example, It would be nice to add rules for other tenses and verb forms. Now I have only present and past simple and know about gerunds.
- known concepts and relations. They are the most intuitively extended feature possible. Just add to known relations that there can be “dish for meal” and to known concepts that “fish is meal” and you get “dish for fish” recognised. So I can grow database of known concepts.
Also possible improvements are to give known rules, concepts and relations some priorities and kickstart learning which priorities give better, faster understanding. With better priorities, backtracking will almost never needed. Its intuitive. When you see some unfamiliar text, you may spend some time looking at it before you recognise what it means grammatically – its your “backtracking” at work. But with familiar text, you almost never put your eyes back – it means your first understanding try completes successfully.
No, I don’t think we actually do simple backtracking subconsciously, I think we do “parallel backtracking” – it means there are different neural circuits exploring different understanding options simultaneously and then most successful circuit suppresses others. This may need neural network architecture, but smart. Not just “neural network hammer” that is popular nowadays – when people just teach neural networks as “black boxes” hoping they can solve complex tasks on their own in their own dark way.
Okay enough with text parsing. It is just a small part of by great plan. Next part is to create mindmap from text.

